引言
最近AI圈有个让人眼前一亮的新技术——DeepSeek OCR!说实话,当我第一次看到这个名字时,还以为是传统的OCR工具升级版呢。结果一看介绍,好家伙,这哪是简单的文字识别,简直就是AI界的”乾坤大挪移”啊!
作为一个长期关注AI技术发展的”技术宅”,当我第一次看到这个技术时,内心是震撼的。这不仅仅是提升OCR准确率那么简单,而是从根本上解决了大语言模型的一个核心痛点——长文本处理难题。
你有没有遇到过这种情况:跟AI聊着聊着,它就”失忆”了?问它几分钟前说过什么,它却一脸懵逼。这就是长文本处理的难题,而现在DeepSeek OCR可能要改变这一切!
今天就带你深入了解一下这项可能改变AI未来的创新技术!
📌 文章导读:本文将从技术原理、创新点、性能表现、应用场景等多个维度,全面解析DeepSeek OCR这项革命性技术。无论你是AI技术爱好者、开发者还是企业管理者,都能从中获得有价值的信息。
什么是DeepSeek OCR?
DeepSeek OCR是DeepSeek团队最新发布的一个开源模型,但它真正的名字应该是”DeepSeek-OCR: Contexts Optical Compression”(上下文光学压缩)。说实话,这个名字有点绕口,但确实更能体现它的核心价值。
简单来说,DeepSeek OCR就像是给AI装上了一双”火眼金睛”,让它能一眼看穿文档的本质,而不是傻乎乎地一个字一个字去读。
简单来说,DeepSeek OCR不是简单地识别图片中的文字,而是通过一种革命性的方法,将大量的文本信息”压缩”成图像,然后再让AI去”看图识字”。这种做法可以大幅减少AI处理长文本时的计算负担。
是不是听起来有点玄乎?别急,我们一步步来拆解。
传统OCR的局限性
在了解DeepSeek OCR之前,我们先来看看传统OCR有什么问题:
说实话,传统OCR就像是一个”书呆子”,只会按部就班地工作。你给它一张图片,它就老老实实地把每个字都识别出来,但遇到复杂情况就容易”抓瞎”。
传统的OCR就像一个”逐字阅读”的机器,它会把图片中的每个字都识别出来,然后转换成文本。这种方式在处理简单文档时效果不错,但遇到复杂场景就力不从心了:
1. 表格混乱:遇到复杂的表格,传统OCR往往无法正确识别行列关系
2. 公式识别困难:数学公式、化学方程式等复杂结构难以准确识别
3. 版式丢失:原文档的排版、格式信息完全丢失
4. 处理效率低:面对长文档时,处理速度慢且容易出错
DeepSeek OCR的革命性创新
DeepSeek OCR的核心创新在于它提出了一个全新的思路:用视觉代替文本。
这个想法是不是很酷?说实话,当我第一次理解这个概念时,脑子里立马浮现出一个画面:AI不再是那个死板的”书呆子”,而是变成了一个会”扫视”的聪明学生。
就像是我们人类看书一样,不是逐字逐句地读,而是先扫一眼整体布局,再重点阅读感兴趣的部分。DeepSeek OCR就是让AI也学会这种”一目十行”的本领!
你想想,这该有多高效?
核心原理
想象一下你是如何阅读一份报纸的:
- 你不会逐字逐句地读,而是先扫视全局
- 通过标题、图片和布局快速抓住重点
- 然后再深入阅读感兴趣的部分
DeepSeek OCR正是借鉴了人类的这种阅读方式:
1. 视觉压缩:将长文本、复杂文档转换成图像
2. Token瘦身:同样的信息量,用图像表示消耗的Token远少于纯文本
3. 智能解码:让AI通过”看图”来理解和提取信息
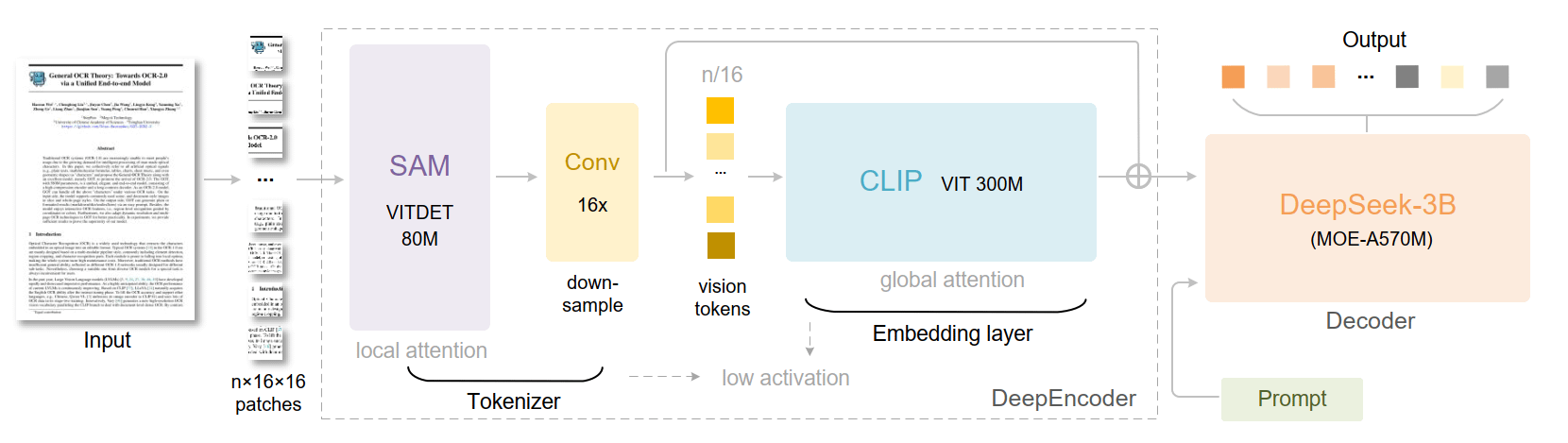
技术架构
DeepSeek OCR采用了独特的”两段式”架构:
DeepEncoder(视觉压缩引擎):
- 前端:SAM-base模块,负责捕捉图像细节
- 中间:16倍卷积压缩层,大幅减少token数量
- 后端:CLIP-large模块,提取全局语义信息
DeepSeek-3B-MoE解码器:
- 采用稀疏专家模型架构
- 总参数3B,但每次只激活部分专家(约5.7亿参数)
- 实现”小开销,大智慧”的效果
令人惊叹的性能表现
DeepSeek OCR的性能表现真的让人印象深刻:
压缩效果
– 10倍压缩:保持97%的识别精度
– 20倍压缩:仍能维持约60%的准确率
看到这个数据我真的是惊了!10倍压缩还能保持97%的精度,这相当于把一本300页的书压缩成30页,但内容几乎不丢失。这效率提升也太夸张了吧!
这意味着什么?一篇原本需要处理数万个Token的长文档,通过DeepSeek OCR压缩后,可能只需要几千个Token就能处理,效率提升数十倍!
实际应用表现
在OmniDocBench基准测试中:
- 仅用100个视觉token就超越了GOT-OCR2.0(256个token)
- 在使用少于800个视觉token的情况下,性能优于MinerU2.0(平均每页6000+token)
多场景应用能力
DeepSeek OCR不仅仅是一个OCR工具,它在多个场景下都展现出了强大的能力:
1. 复杂文档处理
无论是财务报表、法律合同还是学术论文,DeepSeek OCR都能准确识别并保留原有格式,直接输出Markdown格式的结果。

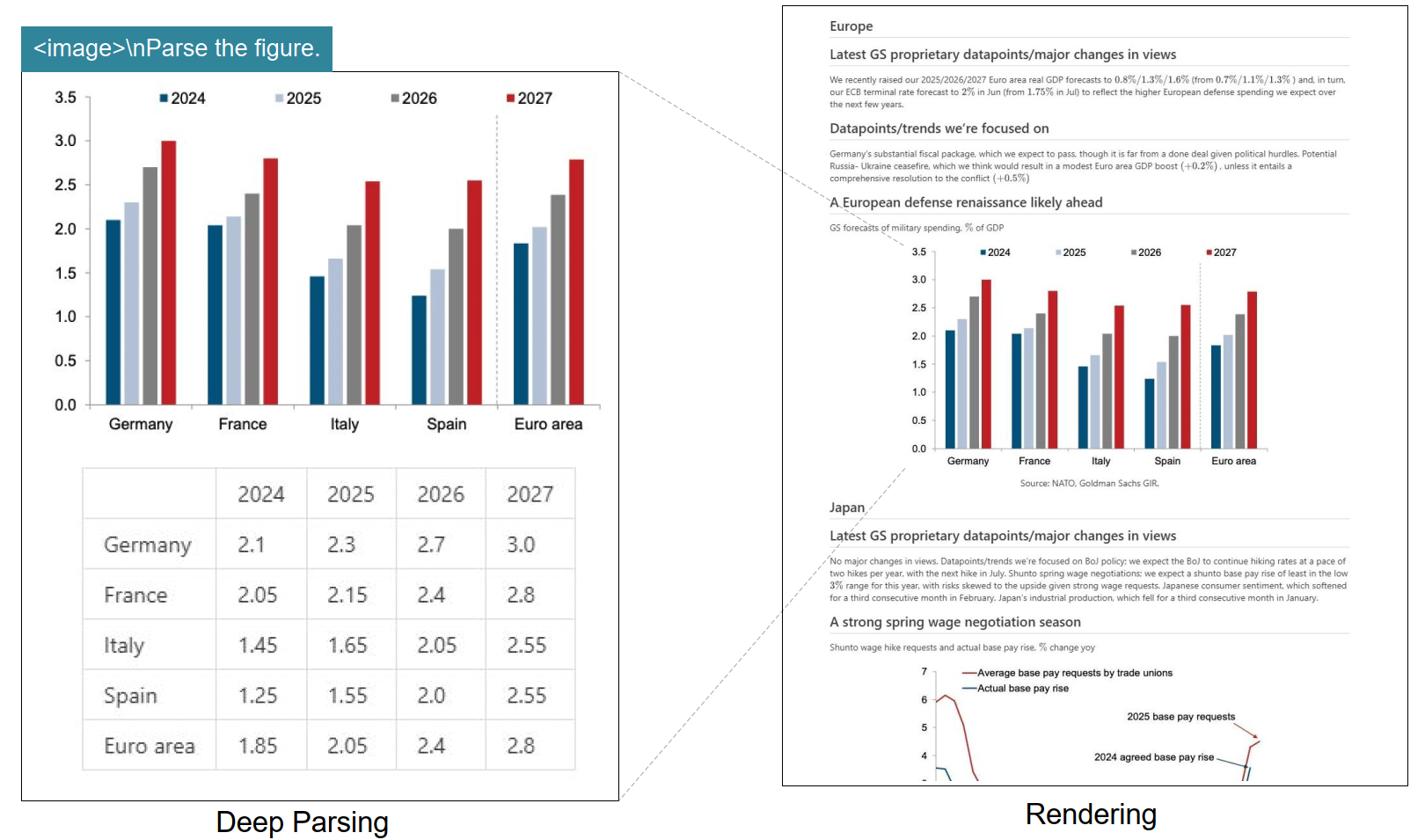

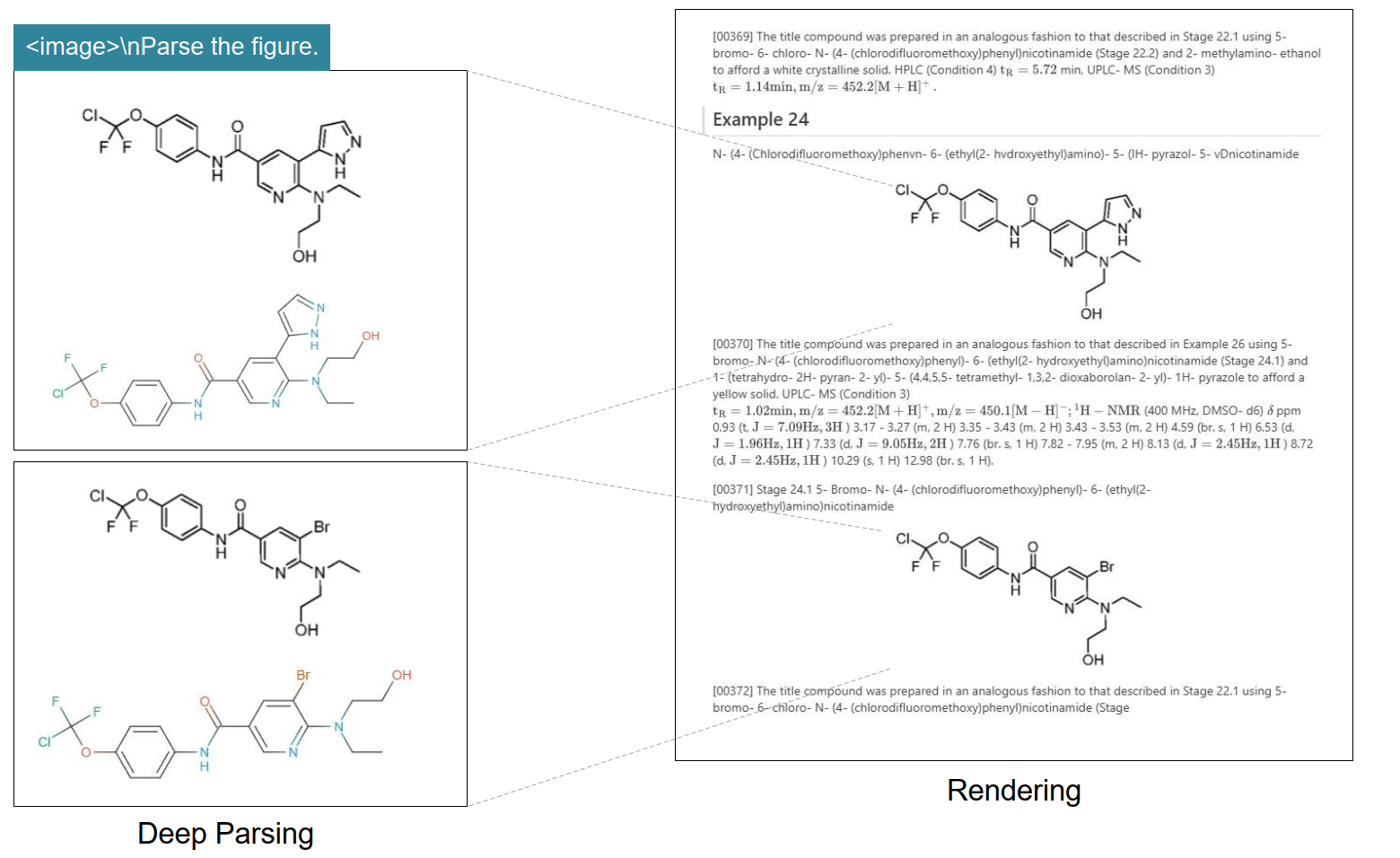
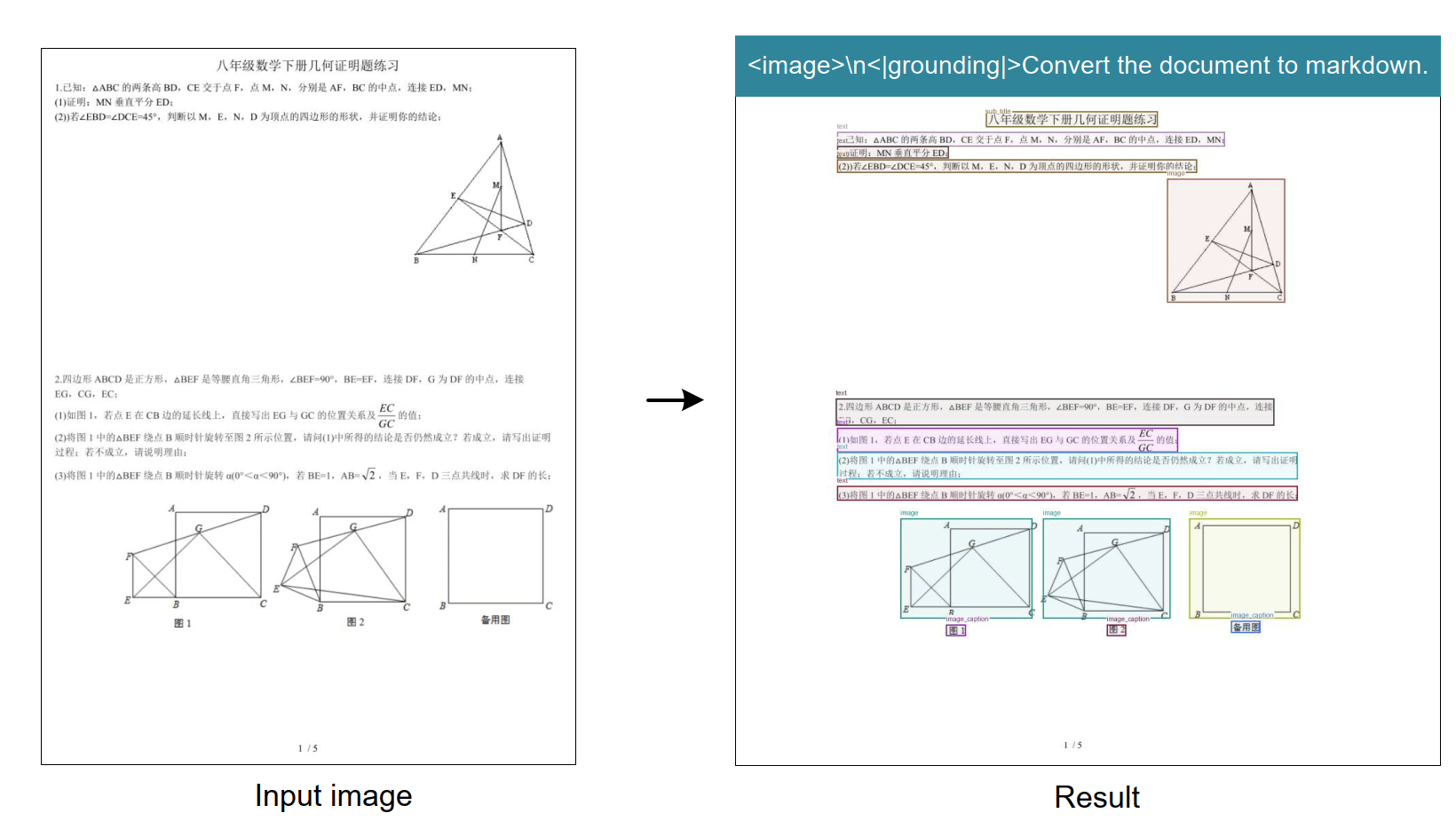
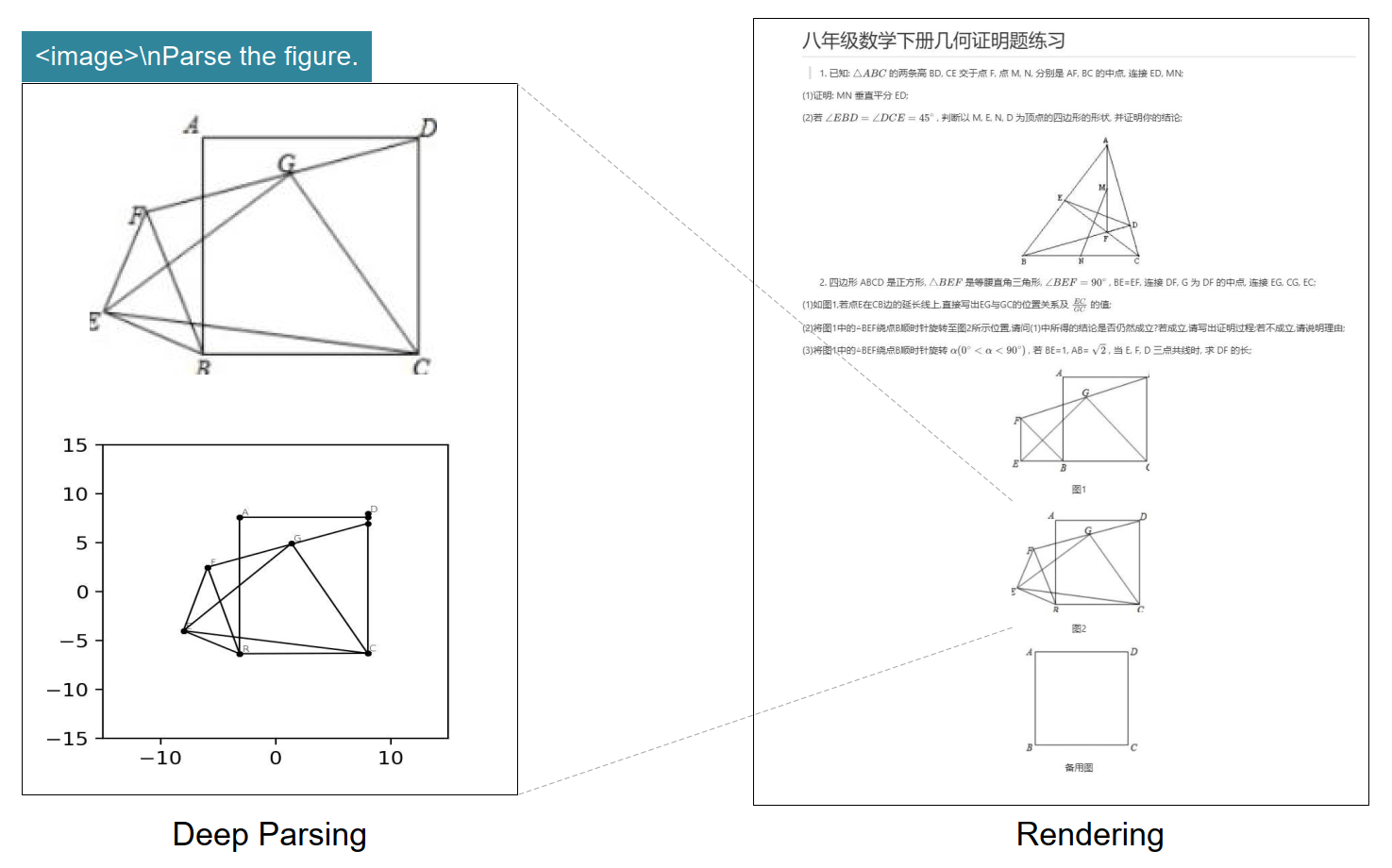
DeepSeek OCR处理复杂文档的效果
2. 图表与公式识别
对于金融报告中的柱状图、学术论文中的数学公式、化学方程式等复杂内容,DeepSeek OCR不仅能识别,还能将其转换为可编辑的结构化数据。
3. 多语言支持
支持包括中文、英文、日文等近100种语言的识别,适用范围极广。
4. 通用视觉理解
除了文档处理,DeepSeek OCR还保留了图像描述、目标检测等通用视觉理解能力。
颠覆性的技术意义
DeepSeek OCR的意义远不止于OCR领域,它实际上为解决大语言模型的核心痛点提供了一个全新的思路。
解决长文本处理难题
大语言模型在处理长文本时面临一个严重问题:随着文本长度增加,计算量呈指数级增长。这就是所谓的”上下文长度难题”。
DeepSeek OCR提供了一个巧妙的解决方案:
- 将历史对话或长文档”拍照”存储
- 通过视觉压缩技术减少token消耗
- 在需要时再解码还原信息
这种方式就像人类的记忆机制——近期的事情记得很清楚,久远的事情会逐渐模糊,但关键信息不会丢失。
为AI”记忆管理”提供新思路
DeepSeek团队在论文中提出了一个非常有趣的观点:可以逐步缩小渲染出的图像,以进一步减少令牌消耗。这个想法的灵感来自于人类记忆的衰退现象。
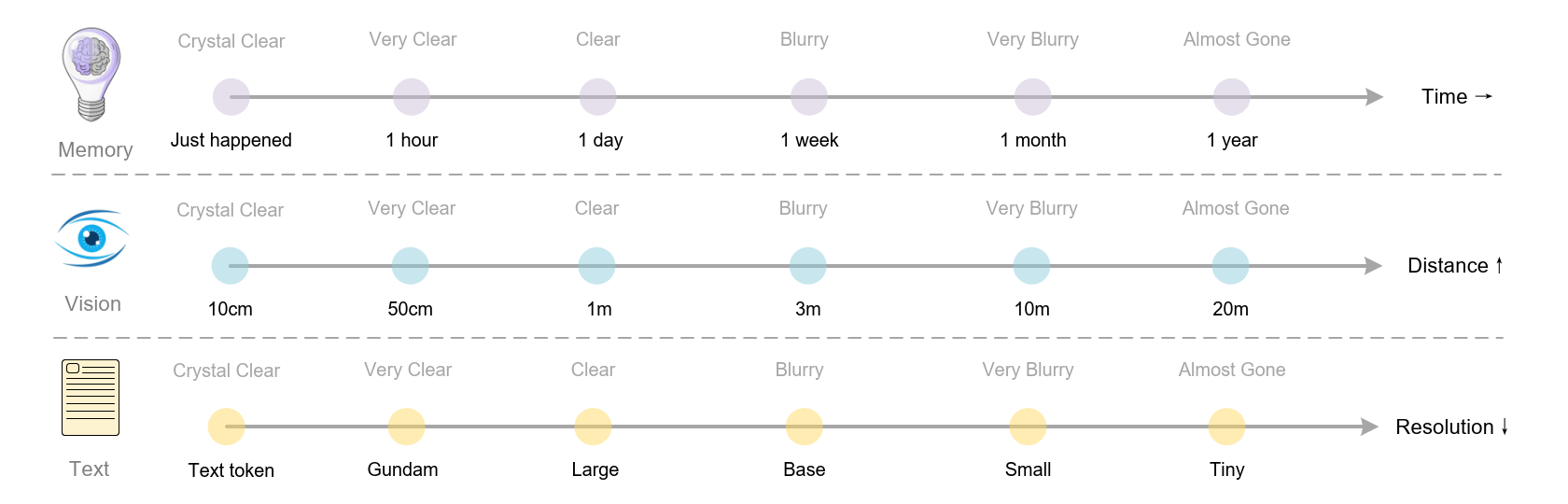
AI记忆管理的类比
通过这种方式,AI可以实现一种类似人类的”可控遗忘机制”:
- 最近的信息保持高保真度
- 久远的记忆通过压缩逐渐”褪色”
- 为新信息保留足够的认知资源
实际应用前景
说了这么多技术原理,你可能想问:这玩意儿到底有什么用?别急,让我给你掰扯掰扯。
DeepSeek OCR的开源为各行各业带来了巨大的应用潜力:
> 💡 小贴士:以下应用场景均基于DeepSeek OCR的技术特性,实际效果可能因具体实现而异。
1. 文档数字化
企业和机构可以高效地将大量纸质文档、PDF文件数字化,而且能保持原有的格式和结构。
想象一下,一个律师事务所有成千上万份合同需要数字化,以前可能需要几十个人忙活好几个月,现在用DeepSeek OCR,可能几天就搞定了!这效率提升是不是很夸张?
2. 知识管理
帮助企业和个人更好地管理和检索海量文档信息,大幅提升工作效率。
想想看,一个研究员面对成千上万份文献,以前可能需要几个月才能整理完毕,现在有了DeepSeek OCR,几天就能完成初步处理,这该有多爽!
3. 教育领域
自动识别和结构化处理教材、试卷、学术论文等教育资源。
对于老师来说,这简直就是福音啊!再也不用 manually 一个个录入题目了,DeepSeek OCR能自动识别试卷内容,还能保持原有的格式结构。
4. 金融行业
高效处理财务报表、合同文件等复杂文档,提升风控和合规审查效率。
5. 法律服务
快速处理法律文书、合同条款等,为律师提供智能辅助。
技术挑战与未来展望
当然了,这么牛的技术也不是完美的。虽然DeepSeek OCR展现出了巨大的潜力,但它也面临着一些挑战:
> ⚠️ 客观评价:任何技术都有其局限性,了解这些挑战有助于我们更好地应用这项技术。
当前局限
1. 压缩比与精度的平衡:更高的压缩比意味着更少的token消耗,但也会导致精度下降。这就像拍照一样,压缩得越狠,画质越模糊。
2. 复杂场景适应性:在极端复杂的文档场景下,仍可能出现识别错误。不过话说回来,哪个技术能做到100%准确呢?
3. 计算资源需求:虽然比传统方法高效,但仍需要一定的计算资源支持。这也很正常,毕竟技术再先进也得有硬件支撑不是?
未来发展方向
说实话,看到这些挑战我反而更兴奋了,因为这意味着还有很多机会等着我们去探索:
> 🚀 未来展望:技术的发展就是一个不断解决问题的过程,每一个挑战都可能孕育着新的突破点。
1. 精度优化:在保持高压缩比的同时进一步提升识别精度
2. 场景适配:针对特定行业和应用场景进行优化
3. 集成应用:与其他AI技术结合,构建更完整的文档处理解决方案
我觉得DeepSeek团队这次真的是开了个好头,未来可期啊!
结语
DeepSeek OCR的出现,不仅仅是一个OCR工具的升级,更是AI技术发展的一个重要里程碑。它让我们看到了解决大语言模型长文本处理难题的新可能,也为AI的”记忆管理”提供了全新的思路。
说实话,看到这项技术的时候,我真的有点小激动。这不 just 是技术的进步,更是思维方式的突破。从”逐字阅读”到”看图识字”,这个转变太有想象力了!
这项技术的开源,为整个AI社区提供了一个强大的工具。说实话,我已经迫不及待想看看社区里的大神们会用它做出什么有趣的东西了!相信在不久的将来,我们会看到更多基于这一技术的创新应用出现。
对于我们普通用户来说,这意味着更高效、更智能的文档处理体验;对于开发者来说,这提供了一个全新的技术方向;对于整个AI行业来说,这可能是一个新时代的开始。
未来已来,让我们拭目以待!
本文部分内容参考了DeepSeek官方文档及相关技术文章,在此一并致谢。如果你对DeepSeek OCR技术有任何想法或问题,欢迎在评论区留言交流!
👉 关注我们,获取更多AI前沿技术解读!
说实话,写完这篇文章我自己都有点小兴奋。这种技术突破真的让人对未来充满期待。你觉得DeepSeek OCR会带来哪些改变呢?在评论区聊聊你的看法吧!
> 📢 互动话题:
- 你认为DeepSeek OCR最适合应用在哪个领域?
- 如果你是开发者,你会如何利用这项技术?
- 这项技术是否会让你重新思考AI的能力边界?
- 欢迎在评论区分享你的观点!